vLLM
1. 传统内存分配的痛点(为什么浪费严重)
- KV Cache 需要连续大块内存:自回归生成时,序列长度动态增长 → 必须提前预分配一大段连续显存。
- 两大碎片化问题:
- 内部碎片:预分配过多,实际用不完的部分空闲浪费。
- 外部碎片:请求结束释放后,显存出现很多小空洞 → 无法放入新的大请求,即使总空闲够。
- 结果:显存利用率常只有 20–40%,GPU 计算资源严重闲置 → 吞吐量(tokens/s)和并发能力很低。
2. vLLM 的两大革命性优化(直接解决以上两大痛点)
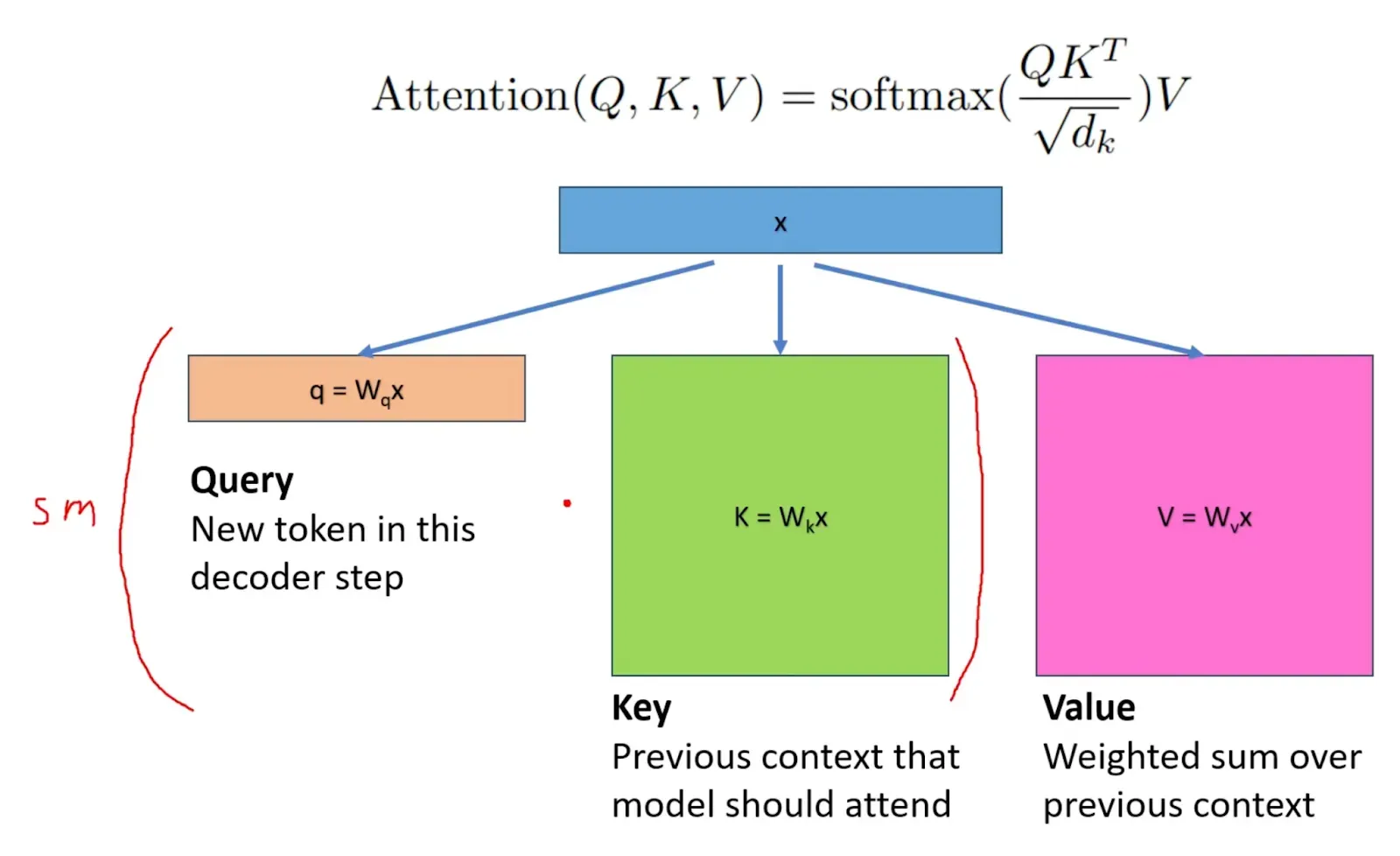
A. PagedAttention(分页注意力)—— 内存分配的“操作系统式革命”
- 借鉴 OS 虚拟内存 + 分页机制:
- 把整个 KV Cache 切成固定大小的 小块(block/page)(通常每块存 16–32 个 token 的 K 和 V)。
- 这些块 不需要连续,可以散落在 GPU 显存的任何地方。
- 核心数据结构:
- 每个请求维护一个 块表(block table):逻辑序列号 → 物理块 ID 的映射表。
- 注意力计算时,通过块表间接访问(自定义 CUDA 内核支持),计算结果和传统连续方式完全等价。
- 带来的巨大收益:
- 近零浪费:内存利用率从 <40% 提升到 >90–95%(碎片几乎消除)。
- 支持 KV 缓存共享/复用(相同 prompt 前缀、prefix caching、多轮对话复用块)。
- 允许动态增长/释放块 → 完美支持变长序列和高并发。
B. Continuous Batching(连续批处理)—— 计算资源的“永不空闲”
- 传统静态批处理:凑够一批请求,一起跑完所有序列才结束 → 快完成的序列空闲 padding,GPU 浪费;必须等最慢的那个结束才能进新请求。
- vLLM 的连续批处理:
- 每生成一个 token(每一步迭代)都 动态调整 batch:
- 已完成的请求 → 立即移除,释放其 Paged KV 块。
- 新请求 → 立即加入当前 batch(如果有空位)。
- 不需要 padding,GPU 始终满载。
- 每生成一个 token(每一步迭代)都 动态调整 batch:
- 必须依赖 PagedAttention:只有非连续块 + 块表,才能零开销地移除中间序列、插入新序列。
- 收益:
- GPU 利用率接近 100%。
- 吞吐量提升 2–24×(视模型、硬件、负载)。
- 平均延迟更低(快请求不被慢请求拖累),p50/p90 显著改善。
3. vLLM 整体架构简图
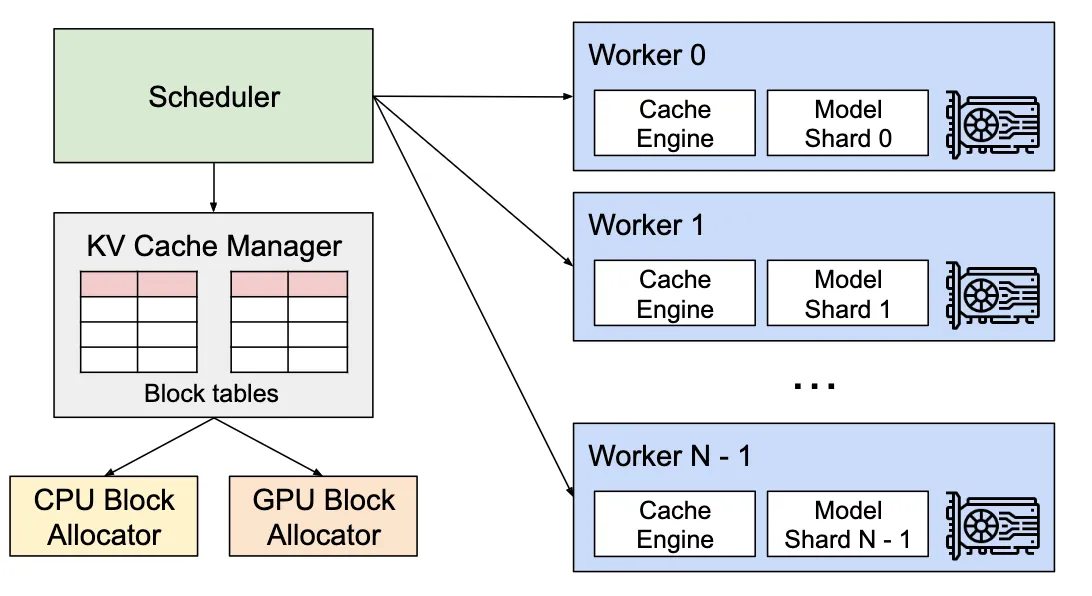
- API Server(FastAPI + Uvicorn):OpenAI 兼容接口,高并发异步处理。
- 高性能推理内核(PagedAttention):分页 KV Cache → 近零浪费 + 共享复用。
- 推理调度器(Scheduler):Continuous Batching + 抢占式调度 → GPU 永不空闲、动态进出请求。
总结
vLLM 把操作系统经典的“虚拟内存分页”思想移植到 GPU KV Cache 上(PagedAttention),再配合“每步都动态重组 batch”的调度(Continuous Batching),彻底解决了传统推理的内存碎片 + GPU 空闲两大杀手,从而在相同硬件上实现数倍到数十倍的吞吐量提升,成为 2025–2026 年生产级 LLM 推理的事实标准。
vLLM = 高性能推理内核 + 推理调度器 + API Server
「略」autoDL租赁机器
…
环境准备
#安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
#保存uv 到zshrc
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.zshrc
source ~/.zshrc
#初始化uv
uv venv llm
#激活
source llm/bin/activate
#安装vllm
uv pip install vllm
#安装 huggingface_hub 的 CLI
uv pip install vllm 'huggingface_hub[cli]'
#如果有网络问题,可以配置清华源
UV_HTTP_TIMEOUT=300 uv pip install 'huggingface_hub[cli]' --index-url https://pypi.tuna.tsinghua.edu.cn/simple
# huggingface-cli login --token hf_你的token
huggingface-cli login --token hf_REDACTED
#使用modelscope
uv pip install modelscope
# 下载到 ~/models/qwen2-1.5b-instruct(推荐用这个路径)
modelscope download --model qwen/Qwen2-1.5B-Instruct \
--local_dir ~/models/qwen2-1.5b-instruct
uv run vllm serve ~/models/qwen2-1.5b-instruct \
--dtype float16 \
--tokenizer-mode auto \
--port 8000 \
--enforce-eager \
--served-model-name qwen2-1.5b-instruct
#completion的方式回答
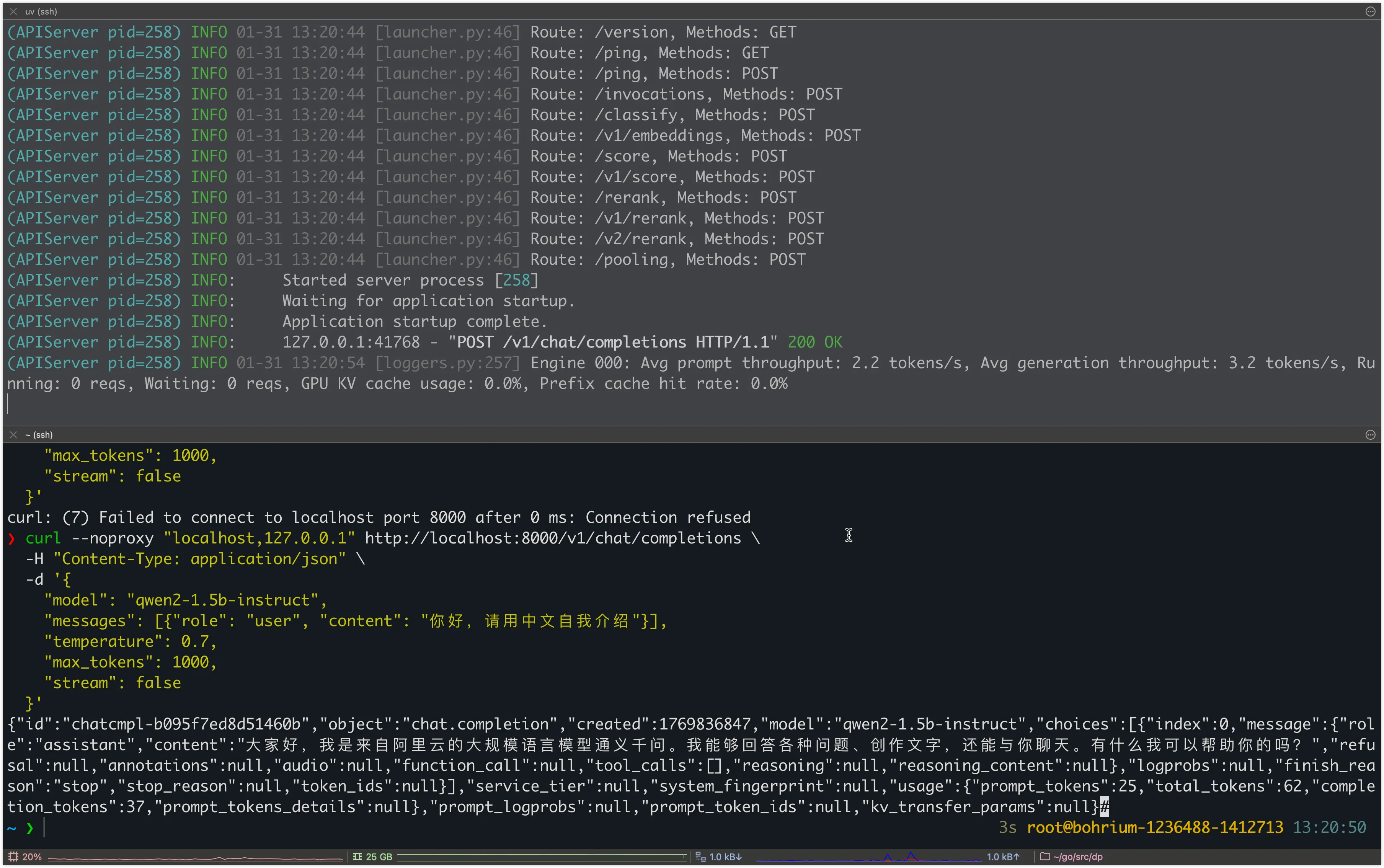
curl --noproxy "localhost,127.0.0.1" http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2-1.5b-instruct",
"messages": [{"role": "user", "content": "你好,请用中文自我介绍"}],
"temperature": 0.7,
"max_tokens": 1000,
"stream": false
}'
{"id":"chatcmpl-8c90e7a1ec5eee15","object":"chat.completion","created":1769747304,"model":"qwen2-1.5b-instruct","choices":[{"index":0,"message":{"role":"assistant","content":"你好!我叫小冰,是一个AI语言模型。我可以回答各种问题,提供信息和建议,并帮助你完成任务。请告诉我你需要什么帮助?","refusal":null,"annotations":null,"audio":null,"function_call":null,"tool_calls":[],"reasoning":null,"reasoning_content":null},"logprobs":null,"finish_reason":"stop","stop_reason":null,"token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":25,"total_tokens":59,"completion_tokens":34,"prompt_tokens_details":null},"prompt_logprobs":null,"prompt_token_ids":null,"kv_transfer_params":null}
# streaming方式回答
curl --noproxy "localhost,127.0.0.1" http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-N \
-d '{
"model": "qwen2-1.5b-instruct",
"messages": [{"role": "user", "content": "你好,请用中文自我介绍"}],
"temperature": 0.7,
"max_tokens": 1000,
"stream": true
}'ssh配置
#本地生成key
ssh-keygen -t ed25519
# 把公钥放到远端
cat ~/.ssh/xxx.pub
#复制到远端
mkdir ~/.ssh && vim ~/.ssh/authorized_keys
#配置本地
vim ~/.ssh/config
Host bohrium
HostName smha1424463.bohrium.tech
User root
IdentityFile ~/.ssh/id_ed25519