Redis的高可用(HA High Avalibility)要解决的是:
- 避免单点故障
- 保证数据尽可能不丢失
- 保证服务队外不中断
Redis 官方给出了三套HA的框架
| 特性 | 主从复制 | 哨兵模式 | 切片集群 |
|---|---|---|---|
| 数据分布 | 每个节点保存全量数据 | 每个节点保存全量数据 | 数据分片存储 |
| 读写分离 | ✓ | ✓ | ✓ |
| 自动故障转移 | ✗ | ✓ | ✓ |
| 扩展性 | 低 | 中 | 高 |
| 部署复杂度 | 简单 | 中等 | 复杂 |
| 维护成本 | 低 | 中 | 高 |
| 适用数据量 | GB 级别 | TB 级别 | PB 级别 |
主从复制(Master-Slave)
主从式高可用的基础,是哨兵和cluster的底层依赖。
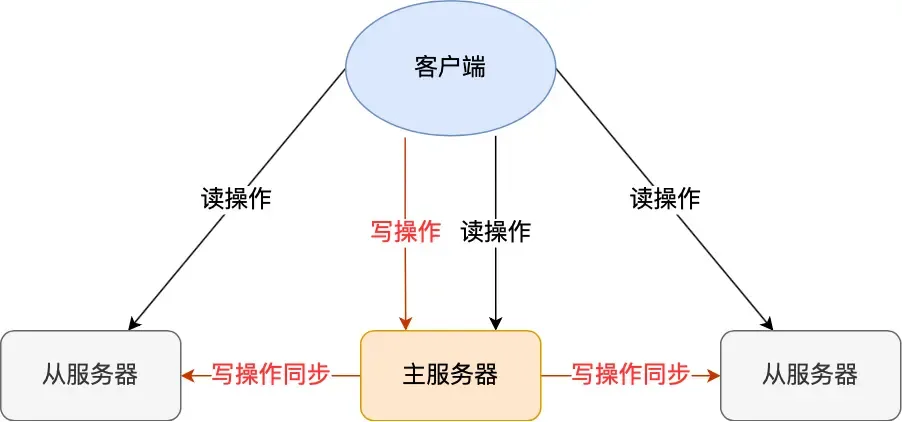
基本原理
- 主节点负责写操作
- 从节点负责读操作
- 主节点数据自动同步到从节点
对于全量复制而言
1) slave 发 PSYNC / SYNC 请求
2) master 执行 RDB 快照 → 发送 RDB 给 slave
3) master 在发送 RDB 的同时,将新的写命令放入 replication buffer
4) slave 加载 RDB 后,再接收 replication buffer 中的增量数据slave初次连接时必须执行全量复制,过程耗时长,网络、磁盘负载较高
对于增量复制而言
当主从短暂断开后,slave可以继续同步
- master保留自己的rep backlog buffer
- slave发送自己的replication offset
- master按照offset差异,发送缺失的命令
其中有一个比较重要的点:如果 backlog 太小导致丢失 offset 范围 → 回退到全量同步(代价很大)
优缺点
pros:
- 读写分离,提高性能
- 数据备份
- 实现简单
cons:
- 主节点故障需要手动切换
- 无法自动故障转移
- 无法实现自动化运维
哨兵模式(Sentinel)
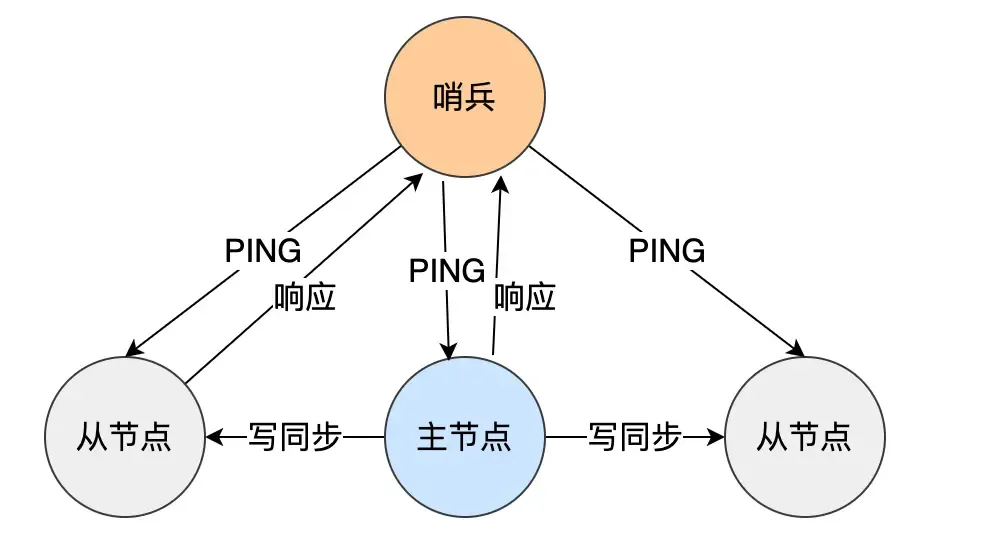
主从模式下,当主节点fail时,写入会中断。所以需要拥有failover的能力。
基本原理
- 在主从复制基础上,增加哨兵节点监控集群状态
- 自动进行故障检测和转移
- 提供自动化运维能力
哨兵的功能
每个哨兵对master做PING/PONG心跳检测,多哨兵经投票后判断matser状态。
- 主节点自动故障检测
- 自动切换(failover)
- 通知客户端新的master地址
哨兵如何选择新的master
优先级规则:
- slave priority(redis.conf 配置)
- replication offset(数据最新)
- runid(字典序最小)
配置
# 哨兵配置
sentinel monitor mymaster 192.168.1.10 6379 2 # 至少2个哨兵同意才能判定主节点故障
sentinel down-after-milliseconds mymaster 30000 # 30秒没有响应则判定为主观下线
sentinel failover-timeout mymaster 180000 # 故障转移超时时间
sentinel parallel-syncs mymaster 1 # 同时同步的从节点数量
# 主节点配置
min-slaves-to-write 1 # 至少有1个从节点连接
min-slaves-max-lag 10 # 从节点最大延迟秒数切片集群(Redis Cluster)
哨兵模式解决了主从模式下的不可failover问题。但是单node的内存往往是有瓶颈的。所以可以通过分布式的方式——分片,通过分片实现现行扩展,实现多主多从。
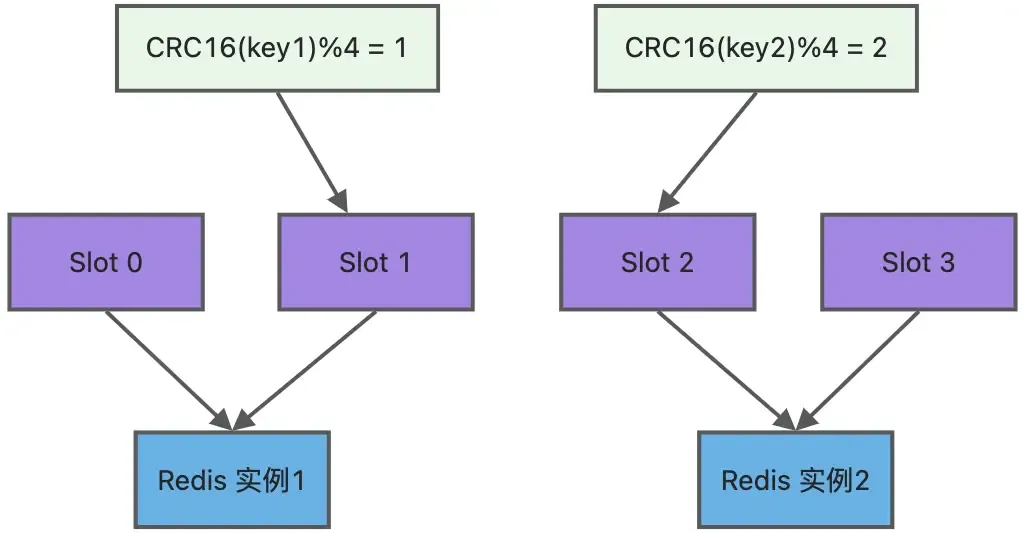
基本原理
- 数据自动分片到多个节点
- 每个分片可以有主从节点
- 支持自动故障转移
实现步骤
# 1. 配置集群节点(redis.conf)
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
# 2. 创建集群
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 \\
127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 \\
--cluster-replicas 1数据分片机制
- 使用 16384 个哈希槽
- 根据 key 的 CRC16 值对 16384 取模来分配
- 每个节点负责一部分哈希槽
故障转移
- 节点间通过 Gossip 协议通信
- 自动检测节点故障
- 从节点自动升级为主节点
新增节点是否需要数据迁移?
新增 Master 节点默认不负责任何 slot,因此必须通过 reshard 将部分 slot 从旧节点迁移到新节点。迁移采取在线 MIGRATE 方式,逐 key 搬迁,不影响服务。
删除节点是否需要数据迁移?
删除 Master 节点必须先将其 slot 迁移到其他 Master,否则无法删除;删除 Slave 节点则不需要迁移数据。
主从数据不一致问题
主从不一致本质是 Redis 的主从复制是异步的,导致读从时可能读到旧数据。
一般从三个层面处理:
- 业务层避免跨主从读写:强一致场景全部读写走主节点,读从仅用于弱一致需求。
- 使用 WAIT 命令增强一致性:写入后等待从节点确认,可实现更强的一致性保障。
- 使用 Redis Cluster:默认读主,自动故障切换,减少人为架构处理一致性问题。
常见真实做法是“强一致读主、弱一致读从”。
各种方案的整体对比
| 方案 | 高可用 | 数据一致性 | 扩展性 | 使用场景 |
|---|---|---|---|---|
| 主从复制 | 中 | 弱一致性 | 不支持横向扩容 | 单节点读扩展 |
| Sentinel | 高 | 弱一致性 | 不扩容,只 HA | 高可用读写场景 |
| Cluster | 高 | 弱一致性 | 可横向扩容(分片) | 超大规模集群、云原生 |
| 第三方 Proxy(Codis/Twemproxy) | 中 | 改善一致性,但依赖 proxy | 可扩容 | 大规模缓存(简化客户端) |