🥅 从方法论角度总结常用的 Prompt 技法。
提示工程的核心方法论
提示技术

提示工程本质上是在不改变模型权重的情况下,通过精心设计的输入文本,最大化引导大语言模型产生期望输出的过程。
它可以被看作以下几个层级的递进式优化策略:
- 基础层:让模型“明白我要什么”
- 示范层:让模型“知道怎么做才对”
- 推理层:让模型“学会思考”
- 可靠性层:让模型“减少出错”
- 探索层:让模型“考虑多种可能性”
- 工具层:让模型“走出封闭世界”
- 风格/约束层:让模型“按指定格式和角色输出”
常用技法分类与方法论对比
| 层级 | 技法名称 | 核心方法论思路 | 典型提升场景 | 主要适用任务类型 | 实现成本 | 代表性触发词 / 做法 |
|---|---|---|---|---|---|---|
| 基础 | Zero-shot | 直接指令,依赖模型已有知识 | 简单、常见任务 | 翻译、摘要、简单问答 | 极低 | 直接写任务描述 |
| 示范 | Few-shot | 通过少量高质量示例“教”模型输出格式与逻辑 | 需要严格格式或特定风格 | 分类、抽取、改写、结构化输出 | 低 | 给 2–6 个 input → output 示例 |
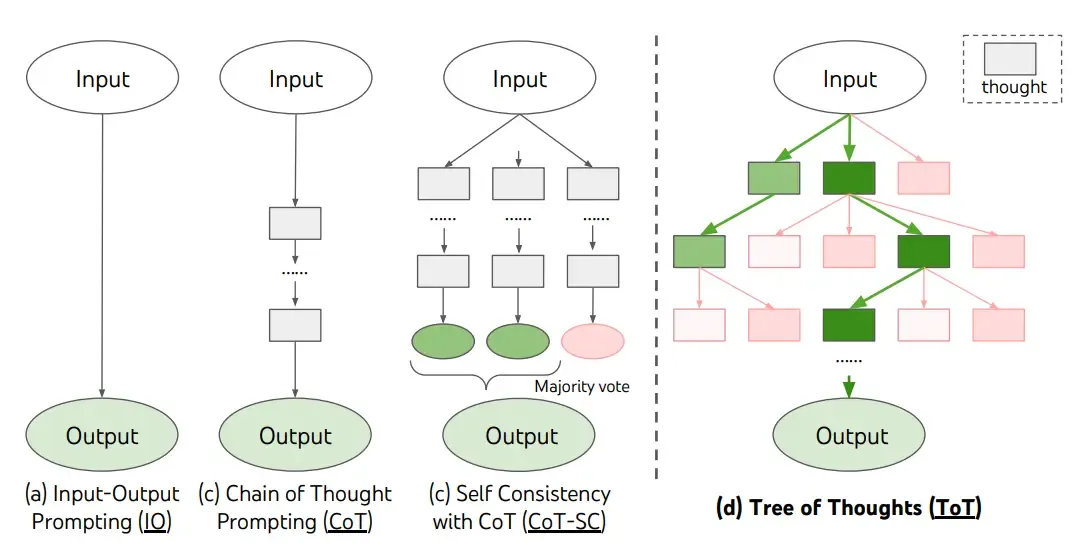
| 推理 | Chain-of-Thought (CoT) | 强制显式生成中间推理步骤,降低单步跳跃难度 | 数学、逻辑、复杂推理 | 数学题、逻辑推理、多步问题 | 低 | “一步一步思考”“Let’s think step by step” |
| 推理 | Zero-shot CoT | 极简版 CoT,无需示例 | 快速提升推理能力 | 同 CoT | 极低 | 只加一句“让我们一步一步思考” |
| 可靠性 | Self-Consistency | 多次独立采样 + 多数投票 / 最一致答案 | 减少单次推理的偶然错误 | 数学、选择题、确定性答案 | 中 | CoT + 多采样(5–15次)+ 投票 |
| 探索 | Tree-of-Thoughts (ToT) | 树状多路径生成 → 评估 → 选择/剪枝/回溯 | 需要探索多种可能性的复杂问题 | 规划、策略、解谜、创意设计 | 高 | 生成多个思路 → 打分 → 深入最优分支 |
| 探索 | Graph-of-Thoughts (GoT) | 更自由的非树状依赖关系图推理 | 高度非线性、相互依赖的推理 | 复杂分析、多维度综合 | 很高 | 思路之间建立显式连接关系 |
| 工具 | ReAct | 交替进行 思考(Thought) → 行动(Action) → 观察(Observation) | 需要外部信息、工具、实时知识 | 知识问答、搜索、计算、API 调用 | 中–高 | Thought → Action → Observation 循环 |
| 工具 | RAG | 检索 → 注入上下文 → 生成 | 知识密集型、最新信息、私有数据 | 问答、文档检索、知识库查询 | 中–高 | 先检索 → 把检索结果塞进 prompt |
| 风格/约束 | Role / Persona Prompting | 赋予模型特定身份,激活对应知识与表达风格 | 需要专业性、特定语气 | 写作、咨询、客服、教学 | 低 | “你是一位……资深……专家” |
| 风格/约束 | System Prompt | 设置全局行为规则、输出格式、禁止事项 | 产品化、批量任务、格式严格 | API 调用、结构化输出、长期对话 | 低 | 系统消息中写规则 + 格式模板 |
| 风格/约束 | Format Constraint | 强制输出特定结构(JSON、表格、Markdown等) | 后处理自动化、程序调用 | 分类、抽取、结构化生成 | 低 | 明确写出期望的 JSON 结构或表格格式 |
| 自动优化 | APE / OPRO / Auto-CoT | 让模型自己生成/优化 prompt | 追求极致效果、批量任务 | 任何任务(尤其是已知效果不佳时) | 中–高 | 让模型“写一个更好的 prompt” |
方法论选择快速决策路径
任务来了
↓
是否非常简单、模型大概率会做对? → Zero-shot
↓ 否
需要严格的输出格式或风格? → Few-shot + Format Constraint
↓ 否
涉及多步推理、计算、逻辑? → CoT(或 Zero-shot CoT)
↓ 否
答案正确率非常重要、允许一定计算成本? → CoT + Self-Consistency
↓ 否
问题有多种合理路径、容易陷入局部最优? → ToT 或 GoT
↓ 否
需要外部知识、工具、最新信息? → ReAct 或 RAG
↓ 否
需要特定专业性、语气、角色? → Role Prompt + System Prompt
↓ 最后
希望进一步提升? → 尝试 Auto 系列(APE / OPRO)或 Emotion Prompting工程实践中的关键取舍
- 成本 vs 效果:Zero-shot → Few-shot → CoT → Self-Consistency → ToT/ReAct(成本递增,效果递增)
- 速度 vs 质量:temperature 低 + 单次推理 更快;temperature 高 + Self-Consistency 更稳
- 确定性 vs 创造性:低 temperature / 低 top_p → 更确定;高 temperature / 高 top_p → 更多样
- 可解释性:CoT、ToT、ReAct 推理过程可见,Self-Consistency 本身不可解释但结果更可靠
OpenAI 模型调用参数设置推荐
| 场景 | temperature | top_p | max_tokens | frequency_penalty | presence_penalty | 推荐理由 / 备注 |
|---|---|---|---|---|---|---|
| 数学、逻辑、结构化输出 | 0.0–0.3 | 0.9–1.0 | 任务所需(通常 512–2048) | 0.0–0.2 | 0.0–0.1 | 最高确定性,减少幻觉 |
| 普通 CoT / 推理任务 | 0.3–0.6 | 0.95 | 1024–4096 | 0.1–0.3 | 0.1–0.2 | 平衡确定性与少量多样性 |
| Self-Consistency | 0.5–0.8 | 0.95–1.0 | 1024–4096 | 0.0–0.2 | 0.0 | 需要多样性推理路径,之后再投票 |
| 创意写作、脑暴 | 0.8–1.0 | 0.95–1.0 | 2048–8192 | 0.3–0.6 | 0.3–0.6 | 增加多样性,减少重复 |
| 角色扮演、长文本生成 | 0.7–0.9 | 0.95 | 4096+ | 0.2–0.5 | 0.2–0.4 | 保持风格一致,同时有一定创造性 |
| 结构化 JSON 输出 | 0.0–0.2 | 1.0 | 按需 | 0.0 | 0.0 | 配合 response_format={“type”: “json_object”} 使用 |
| 批量处理 / 成本敏感 | 0.0–0.4 | 0.9 | 严格限制 | 0.0 | 0.0 | 优先速度与成本 |
通用建议
- 大多数时候只调 temperature 就够了,top_p 保持默认 1.0
- Self-Consistency 必须把 temperature 调高,否则采样路径会高度重复。
- 强制 JSON 输出时一定要加 response_format={“type”: “json_object”}(o1、gpt-4o、gpt-4-turbo 等支持)
- 生产环境推荐同时设置 max_tokens + stop 序列,避免无限输出